[아이티비즈 박채균 기자] 엔비디아가 엔비디아 다이나모(NVIDIA Dynamo)를 통해 멀티 노드 추론 성능과 효율성을 향상시키고, 아마존웹서비스(AWS), 구글 클라우드(Google Cloud), 마이크로소프트 애저(Microsoft Azure), 오라클 클라우드 인프라스트럭처(OCI; Oracle Cloud Infrastructure) 등 주요 클라우드 제공업체와 통합해 AI 추론 가속화를 지원한다고 17일 밝혔다.
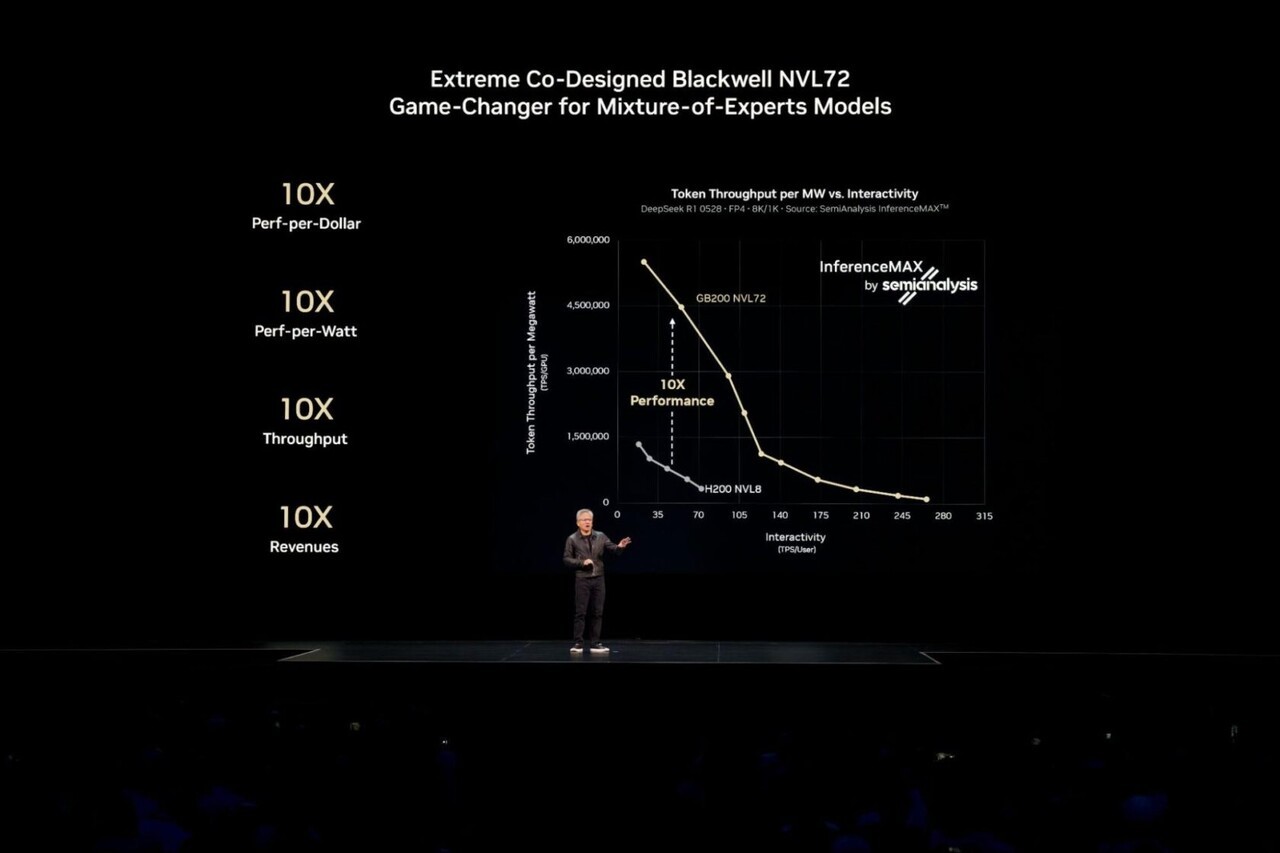
엔비디아 블랙웰(Blackwell)은 최근 세미애널리시스가 실시한 독립형 인퍼런스MAX(InferenceMAX) v1 벤치마크에서 테스트된 모든 모델과 활용 사례 전반에 걸쳐 가장 높은 성능과 효율성, 그리고 가장 낮은 총소유비용(TCO)을 제공했다.
대규모 전문가 혼합 방식(MoE; mixture-of-experts) 모델과 같은 오늘날 가장 복잡한 AI 모델에서 이러한 업계 최고 수준의 성능을 달성하려면, 수백만 명의 동시 사용자에게 서비스를 지원하고 더 빠른 응답을 제공하기 위해 추론 작업을 여러 서버로 분산시켜야 한다.
엔비디아 다이나모 소프트웨어 플랫폼은 이러한 강력한 멀티 노드 기능을 프로덕션 환경에서 지원해, 기업이 기존 클라우드 환경 전반에서도 동일한 벤치마크 최고 수준의 성능과 효율성을 달성할 수 있다.
단일 GPU 또는 서버에 탑재 가능한 AI 모델의 경우, 개발자들은 높은 처리량을 제공하기 위해 여러 노드에 걸쳐 동일한 모델 복제본을 병렬로 실행하는 경우가 많다. 시그널65 수석 애널리스트인 러스 펠로우즈는 최근 발표한 논문에서 이 접근법이 72개의 엔비디아 블랙웰 울트라(Ultra) GPU를 활용해 110만 토큰 처리 속도(TPS)라는 업계 최초의 기록적인 처리량을 달성했다고 밝혔다.
AI 모델을 확장해 다수의 동시 사용자를 실시간으로 지원하거나, 입력 시퀀스가 긴 고난도 워크로드를 처리할 때, 분산형 서빙(disaggregated serving) 기술을 활용하면 성능과 효율성을 더욱 향상시킬 수 있다.
AI 모델 서비스는 입력 프롬프트를 처리하는 프리필(prefill)과 출력을 생성하는 디코드(decode) 두 단계로 구성된다. 기존 방식에서는 두 단계 모두 동일한 GPU에서 실행됐는데, 이로 인해 비효율성과 리소스 병목 현상을 유발할 수 있었다.
분산형 서빙은 이러한 문제를 각각 독립적으로 최적화된 GPU로 작업을 지능적으로 분산함으로써 해결한다. 이를 통해 워크로드의 각 부분이 해당 작업에 가장 적합한 최적화 기법을 활용해 실행되도록 보장해 전체 성능을 극대화한다. 딥시크-R1(DeepSeek-R1)과 같은 최신 대규모 AI 추론과 MoE 모델에서는 분산 서비스가 필수적이다.
엔비디아 다이나모는 이러한 분산형 서빙 기능을 GPU 클러스터 전반에서 프로덕션 규모로 손쉽게 구현할 수 있도록 하며, 이미 그 가치를 입증하고 있다.
대규모 AI 훈련에서 그랬던 것처럼, 컨테이너화된 애플리케이션 관리의 업계 표준인 쿠버네티스(Kubernetes)는 엔터프라이즈 규모의 AI 배포를 위해 수십 개 또는 수백 개의 노드에 걸쳐 분산형 서빙을 확장하는 데 최적화돼 있다.
현재 엔비디아 다이나모가 주요 클라우드 제공업체의 관리형 쿠버네티스 서비스에 통합됨에 따라, 고객은 GB200, GB300 NVL72를 포함한 엔비디아 블랙웰 시스템 전반에서 멀티 노드 추론을 확장할 수 있으며, 이는 엔터프라이즈 AI 배포에 요구되는 성능, 유연성, 안정성을 제공한다.
